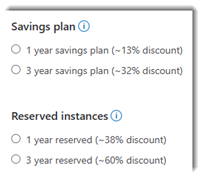
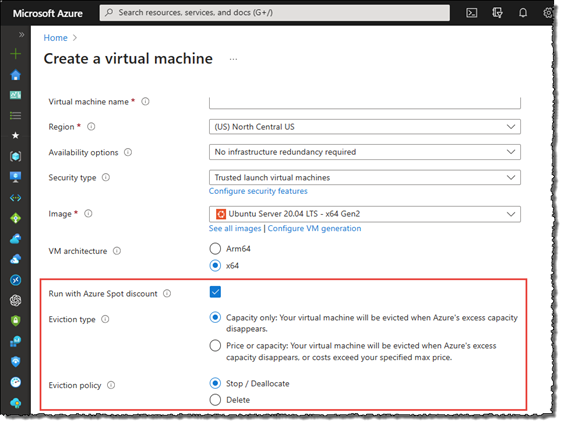
I have compiled the following information to help you better understand “Saving plan” and “Reserve instances” when using Pricing Calculator as shown on the left.
For Windows VMs and SQL Database, the saving plan discount doesn’t apply to the software costs. You may be able to cover the licensing costs with Azure Hybrid Benefit.
Discount auto-applies to the resource usage that matches the attributes you select when you buy the reservation including: SKU, Region (where applicable); and Reservation scope
Two core approaches: traditional and Azure Virtual WAN
The above document has a topology diagram for each model.
Feature
Traditional Azure Network Topology
Azure Virtual WAN Network Topology
Highlights
Customer-managed routing and security
An Azure subscription can create up to 50 vnets across all regions.
Vnet Peering links two vnets either in the same region or in different regions and enables you to route traffic between them using private IP addresses (carry a nominal charge).
Inbound and outbound traffic is charged at both ends of the peered networks. Network appliances such as VPN Gateway and Application Gateway that are run inside a virtual network are also charged.
A Microsoft-managed networking service providing optimized and automated branch to branch connectivity through Azure.
Virtual WAN allows customers to connect branches to each other and Azure, centralizing their network and security needs with virtual appliances such as firewalls and Azure network and security services.
For IT decision makers, here’s why it’s pertinent to consider Azure Arc:
An integrated management and governance solution that is centralized and unified, providing streamlined control and oversight.
Securely extending your on-premandnon-Azureresources into Azure Resource Manager (ARM), empowering you to:
Define, deploy, and manage resources in a declarative fashion using JSON template for dependencies, configuration settings, policies, etc.
Manage Azure Arc-enabled servers, Kubernetes clusters, and databases as if they were running in Azure with consistent user experience.
Harness your existing Windows and Azure sysadmin skills honed from on-premises deployment.
When connecting to Azure Arc-enabled servers, you may perform many operational functions, just as you would with native Azure VMs including these key supported actions:
Secure non-Azure servers with Microsoft Defender for Endpoint, included through Microsoft Defender for Cloud, for threat detection, vulnerability management, and proactive monitoring for potential security threats. Microsoft Defender for Cloud presents the alerts and remediation suggestions from the threats detected.
Keep an eye on OS, processes, and dependencies along with other resources using VM insights. Additionally collect, store, and analyze OS as well as workload logs, performance data, and events. Which may be injected into Microsoft Sentinel real-time analysis, threat detection, and proactive security measures across the entire IT environment.
Extended Security Updates (ESUs) is enabled by Azure Arc. IT can seamlessly deploy ESUs through Azure Arc in on-premises or multi-cloud environments, right from the Azure portal. In addition to providing a centralized management of security patching, ESUs enabled by Azure Arc is flexible with a pay-as-you-go subscription model compared to the classic ESU offered through the Volume Licensing Center which are purchased in yearly increments.
Azure OpenAI is a service provided by Microsoft Azure that allows users to access OpenAI’s powerful language models, including the GPT-3, Codex, and Embeddings model series. Users can access the service through REST APIs, Python SDK, or a web-based interface in the Azure OpenAI Studio.
Azure OpenAI Service gives customers advanced language AI with OpenAI
GPT-4, GPT-3, Codex, and DALL-E
Models with the enterprise security and privacy of Azure.
Azure OpenAI co-develops the APIs with OpenAI, ensuring compatibility and a smooth transition from one to the other
Enterprise-grade security with role-based access control (RBAC) and private networks
Essentially Security, Privacy, and Trust
Microsoft values a customer’s privacy and security of data. When using Azure AI services, Microsoft may collect and store data to improve the session experience and supportability of models. However, customer data is anonymized and aggregated to protect individual privacy.
Microsoft does not use customer data for fine-tuning or customizing models for individual users.
For building AI systems according to six principles:
Fairness and Inclusiveness
Make the same recommendations to everyone who has similar symptoms, financial circumstances, or professional qualifications.
Reliability and Safety
Operate as originally designed, respond safely to unanticipated conditions, and resist harmful manipulation.
Privacy and Security
Restrict access to resources and operations by user account or group.
Restrict incoming and outgoing network communications.
Encrypt data in transit and at rest.
Scan for vulnerabilities.
Apply and audit configuration policies.
Microsoft has also created two open-source packages that can enable further implementation of privacy and security principles: SmartNoise and Counterfit
Transparency and Accountability
The model interpretability component provides multiple or global, local, and model explanations/views into a model’s behavior.
The people who design and deploy AI systems must be accountable for how their systems operate.
By default, Microsoft-managed encryption keys are used, but you also have the option to use customer-managed keys (CMK) for greater control over encryption key management.
With Azure OpenAI, customers get the security capabilities of Microsoft Azure while running the same models as OpenAI. Azure OpenAI offers private networking, regional availability, and responsible AI content filtering.
Azure OpenAI Service contains neural multi-class classification models aimed at detecting and filtering harmful content; the models cover
four categories: hate, sexual, violence, and self-harm across
four severity levels: safe, low, medium, and high.
The default content filtering is default to filter at the medium severity threshold for all four content harm categories for both prompts and completions. That means that content that is detected at severity level medium or high is filtered, while content detected at severity level low is not filtered by the content filters. The configurability feature is available in preview and allows customers to adjust the settings, separately for prompts and completions, to filter content for each content category at different severity levels.
GPT-3 (4k/16k): A series of models that can understand and generate natural language. This includes the new ChatGPT model.
DALL-E: A series of models that can generate original images from natural language.
Codex: A series of models that can understand and generate code, including translating natural language to code.
Embeddings: A set of models that can understand and use embeddings. An embedding is a special format of data representation that can be easily utilized by machine learning models and algorithms. The embedding is an information dense representation of the semantic meaning of a piece of text. Currently, we offer three families of Embeddings models for different functionalities: similarity, text search, and code search.
AZURE OPENAI ON YOUR DATA
With Azure OpenAI GPT-35-Turbo and GPT-4 models, enable them to provide responses based on your data. You can access Azure OpenAI on your data using a REST API or the web-based interface in the Azure OpenAI Studio to create a solution that connects to your data to enable an enhanced chat experience.
Per the document, Azure OpenAI on your data, Azure OpenAI Service supports the following file types:
Previous models were text-in and text-out, meaning they accepted a prompt string and returned a completion to append to the prompt. However, the GPT-35-Turbo and GPT-4 models are conversation-in and message-out.
Azure OpenAI processes text by breaking it down into tokens. Tokens can be words or just chunks of characters. For example, the word “hamburger” gets broken up into the tokens “ham”, “bur” and “ger”, while a short and common word like “pear” is a single token. Many tokens start with a whitespace, for example “ hello” and “ bye”.
The total number of tokens processed in a given request depends on
the length of your input,
output and
request parameters.
The quantity of tokens being processed will also affect your response latency and throughput for the models.
Pricing will be based on the pay-as-you-go consumption model with a price per unit for each model, which is similar to other Azure AI Services pricing models.
SLA: This describes Microsoft’s commitments for uptime and connectivity for Microsoft Online Services covering Azure, Dynamics 365, Office 365, and Intune.
The system role also known as the system message is included at the beginning of the array. This message provides the initial instructions to the model. You can provide various information in the system role including:
A brief description of the assistant
Personality traits of the assistant
Instructions or rules you would like the assistant to follow
Data or information needed for the model, such as relevant questions from an FAQ
You can customize the system role for your use case or just include basic instructions. The system role/message is optional, but it’s recommended to at least include a basic one to get the best results.
“To simplify our product naming and unify our product family, we’re changing the name of Azure AD to Microsoft Entra ID. Capabilities and licensing plans, sign-in URLs, and APIs remain unchanged, and all existing deployments, configurations, and integrations will continue to work as before. Starting today, you’ll see notifications in the administrator portal, on our websites, in documentation, and in other places where you may interact with Azure AD. We’ll complete the name change from Azure AD to Microsoft Entra ID by the end of 2023. No action is needed from you.
To automatically update scripts, reference this quickstart guide.
May want to upgrade sooner than later since Az PowerShell module runs cross-platform and supports all Azure services including Azure authentication mechanisms.
Despite a simple operation, apply the following sample statements to your environment if experiencing an issue in changing an Azure VM’s BootDiagnostic setting.
ISSUE for
Not able to disable/enable BootDiagoistic of an Azure VM
The same process applies to enabling BootDiagnostic by specifying a vm object with the associated resource group and an intended storage account in step 4.
<#
Disabling Azure VM BootDiagnostic Using PowerShell
The following illustrates the process to disable VM BootDiagnostic.
The statements are intended to be executed manually and in sequence.
#>
# 1. Log in Azure and set the context, as appropriate
Connect-AzAccountstep 4
Get-AzContext
Set-AzContext -Subscription '????' -Tenant '????'
# 2. Specify a target VM
$vmName = 'your vm name'
$vmRG = 'the resource group name of the vm'
# 3. Check the current BootDiagnostics status
($VM = Get-AzVM -ResourceGroupName $vmRG -Name $vmName).DiagnosticsProfile.BootDiagnostics
# 4. Disable BootDiagnostic of the VM
Set-AzVMBootDiagnostic -VM $VM -Disable
# 5. Update the VM settings
Update-AzVM -ResourceGroupName $vmRG -VM $VM
# 6. Check the current BootDiagnostics status and verify the change made
($VM = Get-AzVM -ResourceGroupName $vmRG -Name $vmName).DiagnosticsProfile.BootDiagnostics
# Notice it may take a few minutes for azure portal to reflect
# the changes made to BootDiagnostic.